DeanO Interview
-
hoopstudies
- Posts: 15
- Joined: Thu Apr 21, 2011 3:03 pm
Re: DeanO Interview
Regarding whether sample size affects all metrics the same way...
This isn't true. The models of different player metrics are different and implicitly impart structure and potentially reduce noise relative to one another. It's possible that they increase noise if the model is bad. For example, if this is your data set, you can model it all sorts of ways.
A lot of people would just go linear because it's easy, but, of course, a linear model isn't great here. It's going to have a lot of error. But if you can figure out how the underlying process works using the underlying data, you can actually fit this data perfectly. In this case, using periodic functions with the data would quickly lead you to a better model.
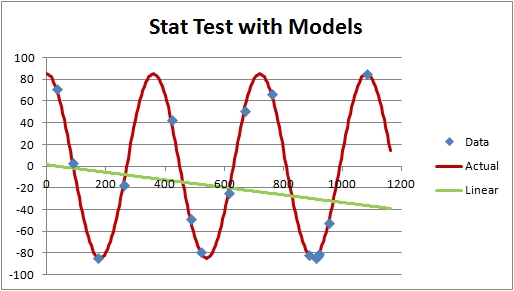
It's the same thing with player value models. Yes, data matters, but models matter a lot, too. RAPM/RPM/APM all use a linear model on net points - O1 + O2 + O3 + O4 + O5 - to estimate the value of players over large samples. That's not a bad model, I would argue, but it does take a lot of data to estimate the value coefficients reasonably. That's why RPM stabilizes it with boxscore data.
Other way to look at it is this. One possession, Westbrook isolates and scores on his man. Using boxscore stats for this one possession gives you some sense of what happened and the value of players - using almost any common sense model. Using an APM approach, effectively all 5 Thunder get the same credit. Stabilizing it with RPM shifts it towards Westbrook. So, all of these have different levels of noise in their estimates of value.
Does that make sense?
Code: Select all
basketballstrategy @bballstrategy 17h17 hours ago
The sample size for boxscore, player-tracking or RAPM splits are identical. If sample size is too small for one, it is too small for all.
A lot of people would just go linear because it's easy, but, of course, a linear model isn't great here. It's going to have a lot of error. But if you can figure out how the underlying process works using the underlying data, you can actually fit this data perfectly. In this case, using periodic functions with the data would quickly lead you to a better model.
It's the same thing with player value models. Yes, data matters, but models matter a lot, too. RAPM/RPM/APM all use a linear model on net points - O1 + O2 + O3 + O4 + O5 - to estimate the value of players over large samples. That's not a bad model, I would argue, but it does take a lot of data to estimate the value coefficients reasonably. That's why RPM stabilizes it with boxscore data.
Other way to look at it is this. One possession, Westbrook isolates and scores on his man. Using boxscore stats for this one possession gives you some sense of what happened and the value of players - using almost any common sense model. Using an APM approach, effectively all 5 Thunder get the same credit. Stabilizing it with RPM shifts it towards Westbrook. So, all of these have different levels of noise in their estimates of value.
Does that make sense?
Re: DeanO Interview
Thanks for exposition and yes it makes sense, as far as it goes.
Player tracking and box score models are linear too when presented as averages, which they almost always are. Anything could be periodic and that would get missed by ALl major metrics presented as averages of any level of set, not just RPM.
One play can't be meaningfully used to judge player quality by ANY metric. Using this test to knock RPM and not others is a selective argument. It is in the thousands of plays that meaning is found. In hundreds of plays, less chance for reliability but still chance for questions, extension, comparison, possible learning.
Almost all talk of APM, RAPM, RPM is of the whole product, black box. RAPM factor and splits answer this complaint. It is isn't simple or simply reliable but what really is? Have you used RAPM factors and / or splits at all? Do you think they have any place or no place in your analysis (even at lineup, player grouping or team level)? Is it just back to the sample size complaint which does apply equally to all metrics at one level (yes some models may interpret / distort more than others but some models "see" or "try to see and interpret everything" and some have absolute blind spots due to lack of technology and data or willful exclusion or inability or unwillingness to differentiate).
Player tracking and box score models are linear too when presented as averages, which they almost always are. Anything could be periodic and that would get missed by ALl major metrics presented as averages of any level of set, not just RPM.
One play can't be meaningfully used to judge player quality by ANY metric. Using this test to knock RPM and not others is a selective argument. It is in the thousands of plays that meaning is found. In hundreds of plays, less chance for reliability but still chance for questions, extension, comparison, possible learning.
Almost all talk of APM, RAPM, RPM is of the whole product, black box. RAPM factor and splits answer this complaint. It is isn't simple or simply reliable but what really is? Have you used RAPM factors and / or splits at all? Do you think they have any place or no place in your analysis (even at lineup, player grouping or team level)? Is it just back to the sample size complaint which does apply equally to all metrics at one level (yes some models may interpret / distort more than others but some models "see" or "try to see and interpret everything" and some have absolute blind spots due to lack of technology and data or willful exclusion or inability or unwillingness to differentiate).
-
hoopstudies
- Posts: 15
- Joined: Thu Apr 21, 2011 3:03 pm
Re: DeanO Interview
Some things stabilize a lot quicker than APM. RPM is one, but boxscore metrics usually do, too. So you can use those other more stable metrics in smaller samples to make assessments.
The inability to be able to split APM/RPM/etc into what happens in the 3rd quarter in the first 5 minutes - that limits its usage also. Even if such splits are less significant, some of them can be very significant if there is a problem and you want a metric that can work at any granularity. You can't do APM on pick/rolls, but people cite the same statistics from Synergy all the time.
Essentially the same point, but I'll phrase it a different way. Those metrics basically say that every possession, Rudy Gobert is worth +6 pts/48 minutes (or per 100 possessions) on defense. More refined models can actually see different values across types of possessions - half court, transition, where he is in pick/roll, when he is defending the post.
The work that has been done to split APM-class models into the Four Factors has been interesting, as well. I think that has more value than just the overall APM work once it's stable.
Another critique of APM-class models is that they don't easily intake extra information, like player tracking or play by play. Can they take it in? People have been developing regressions as a way to do so - the way Jeremias did it for RPM. I'm not sold on whether that is being done right/well yet.
That being said, I still look at these metrics because they come from such a different angle and because, over large enough samples, they should be pretty good. They end up an independent comparison for some of what I do. If they're similar, that's good. If they're different, it forces you to understand why they are different. Ricky Rubio is usually the example of different. APM-class methods love him. Most other methods don't. Discrepant on offense and, to a lesser degree, defense.
The inability to be able to split APM/RPM/etc into what happens in the 3rd quarter in the first 5 minutes - that limits its usage also. Even if such splits are less significant, some of them can be very significant if there is a problem and you want a metric that can work at any granularity. You can't do APM on pick/rolls, but people cite the same statistics from Synergy all the time.
Essentially the same point, but I'll phrase it a different way. Those metrics basically say that every possession, Rudy Gobert is worth +6 pts/48 minutes (or per 100 possessions) on defense. More refined models can actually see different values across types of possessions - half court, transition, where he is in pick/roll, when he is defending the post.
The work that has been done to split APM-class models into the Four Factors has been interesting, as well. I think that has more value than just the overall APM work once it's stable.
Another critique of APM-class models is that they don't easily intake extra information, like player tracking or play by play. Can they take it in? People have been developing regressions as a way to do so - the way Jeremias did it for RPM. I'm not sold on whether that is being done right/well yet.
That being said, I still look at these metrics because they come from such a different angle and because, over large enough samples, they should be pretty good. They end up an independent comparison for some of what I do. If they're similar, that's good. If they're different, it forces you to understand why they are different. Ricky Rubio is usually the example of different. APM-class methods love him. Most other methods don't. Discrepant on offense and, to a lesser degree, defense.
Re: DeanO Interview
So we agree: consider both.
On APM models "can't" do something... yeah, conceptually they can in many cases. Define the split, then do RAPM for that split (and not that split while you are there). It comes down to doing it (big effort blending databases), considering it with appropriate caution, as with any model / split. There are some splits that are too specialized to do perhaps and certainly some too small sample or vaguely defined to have much basis. The meaning issue should be considered for other more straightforward approaches though. Look at Gobert's split data as specified in your example and you better have a lot of caution about giving that data much meaning, significance cuz small sample matters here too, same as with RAPM factors / splits. To do or even say for one but not the other is uneven and imo seems prejudicial.
One can argue / disagree on how much APMs stretch for consistent linear explanation distorts as one can with exclusion / ignorances / clumping in other metrics but it is not a fair case of "issues" with one and clear sailing with the other.
I recognize that what APM type methods could or have done in past don't help with current season public users. But there are folks who could help with that. Teams have less excuse. If the want something, get it, pay for its development.
If others want to add to discussion, go ahead.
On APM models "can't" do something... yeah, conceptually they can in many cases. Define the split, then do RAPM for that split (and not that split while you are there). It comes down to doing it (big effort blending databases), considering it with appropriate caution, as with any model / split. There are some splits that are too specialized to do perhaps and certainly some too small sample or vaguely defined to have much basis. The meaning issue should be considered for other more straightforward approaches though. Look at Gobert's split data as specified in your example and you better have a lot of caution about giving that data much meaning, significance cuz small sample matters here too, same as with RAPM factors / splits. To do or even say for one but not the other is uneven and imo seems prejudicial.
One can argue / disagree on how much APMs stretch for consistent linear explanation distorts as one can with exclusion / ignorances / clumping in other metrics but it is not a fair case of "issues" with one and clear sailing with the other.
I recognize that what APM type methods could or have done in past don't help with current season public users. But there are folks who could help with that. Teams have less excuse. If the want something, get it, pay for its development.
If others want to add to discussion, go ahead.
-
hoopstudies
- Posts: 15
- Joined: Thu Apr 21, 2011 3:03 pm
Re: DeanO Interview
Actually, I look at a lot of player value metrics. I find it useful, even if I have a preference.
So do you bother with RPM? Or do you stick to RAPM?
Yes, you're right that the APM class can do a lot, but that model is more prone to very insignificant results than others because it is assuming constant value per player rather than constant value per role, which is kinda what other methods are doing.
So do you bother with RPM? Or do you stick to RAPM?
Yes, you're right that the APM class can do a lot, but that model is more prone to very insignificant results than others because it is assuming constant value per player rather than constant value per role, which is kinda what other methods are doing.
Re: DeanO Interview
I use RPM because of greater, more consistent availability but as more RAPM is available I'll use it too and compare them. I recently asked JE about a particular case with a large difference. Still wonder if there was a reporting error or something deeper involved.
I'm all for looking at roles and performance in roles by whatever means, accepting data & significance limitations. Position isn't exactly role always but there is substantial overlap. Position based RAPM is feasible, desirable and easier than very specified role or scenario splits.
I'm all for looking at roles and performance in roles by whatever means, accepting data & significance limitations. Position isn't exactly role always but there is substantial overlap. Position based RAPM is feasible, desirable and easier than very specified role or scenario splits.
Re: DeanO Interview
That's a very interesting article, Dean; I appreciate the insight. I didn't realize you were writing articles again!hoopstudies wrote:Actually, I look at a lot of player value metrics. I find it useful, even if I have a preference.
So do you bother with RPM? Or do you stick to RAPM?
Yes, you're right that the APM class can do a lot, but that model is more prone to very insignificant results than others because it is assuming constant value per player rather than constant value per role, which is kinda what other methods are doing.
(As a side note--I'm well aware of the BPM "outlier" issue, generated by Westbrook's assault on the nonlinear terms, and I'm working on solutions. Also, as you probably know, VORP is basically just [BPM - Replacement level] * playing time, so not exactly an independent metric--BPM is the rate stat, VORP is the counting stat.)
This subject boils down to the inherent noise, sample size, and validity of different metrics and components of metrics.
Most of the typical basketball stats noise profiles are basically founded on binomial error. Either you get the rebound or you don't, either you make the shot or you don't. However, depending on how you measure/count these stats, there are different multipliers or sample sizes.
Here's a table:

So that's just the basic binomial error.
Then, depending on the stat, you have the error associated with the coefficient estimates. Some of the above stats are weighted more heavily, some less... so TRB may be noisy, but if it's not weighted heavily in a composite stat, it doesn't significantly contribute to the overall stat's combined error.
The above was purely about box score stats.
APM is a whole different ballgame. The sample sizes are order(s) of magnitudes smaller. Each stint is a single "sample". And the collinearity issues add maybe another order of magnitude to the apparent sample size reduction. That's why APM on the single year scale is basically useless. RAPM of a single year is barely better. Only when you deal with multi year RAPM do you get anything where the noise is low enough to let the valid numbers come through... and then you're just measuring a long-term average anyway, which as Dean noted isn't that useful.
I suspect that if RPM was truly tuned to maximize out of sample testing, the box-score prior for RPM is dominating the regression for most players, particularly for the single-year version.
Re: DeanO Interview
Box score "dominating" isn't necessarily bad or reason not to bother with RAPM. It comes down to try to "see" non- box score impacts, ignore them entirely or pick a few player tracking elements.
TS% and 3pt rate with biggest estimated errors? Lot of current emphasis on those. Offensive projections less reliable? Or would that apply to the defensive flipsides too, if actually used in metric. Many, nope. RAPM implicitly would consider, in the regression. Should RAPM use some kinds of player tracking in the prior instead of double counting it (I think) in PT-PM and Dredge? I'll guess a tentative yes.
TS% and 3pt rate with biggest estimated errors? Lot of current emphasis on those. Offensive projections less reliable? Or would that apply to the defensive flipsides too, if actually used in metric. Many, nope. RAPM implicitly would consider, in the regression. Should RAPM use some kinds of player tracking in the prior instead of double counting it (I think) in PT-PM and Dredge? I'll guess a tentative yes.
-
hoopstudies
- Posts: 15
- Joined: Thu Apr 21, 2011 3:03 pm
Re: DeanO Interview
Not really writing so much as keeping notes. I don't have the time to make the writing good or write about the things that require a lot of work. Wish I did.
I wasn't sure I implemented B-R's VORP right. I may end up having to look at that again someday.
There is a lot of uncertainty in player metrics, so knowing how they reflect the world is useful. What's interesting is that people's opinions are seemingly more consistent than the metrics. The correlation between ESPN's NBA Rank and SI's top 100 and SB Nation's top 100 is quite high. But I think the year to year correlation over the same ranking group is actually smaller than between groups in the same year, which implies a herd effect. Metrics shouldn't have that, so probably should be checked to see if it isn't a herd effect, but just capturing true performance changes.
I wasn't sure I implemented B-R's VORP right. I may end up having to look at that again someday.
There is a lot of uncertainty in player metrics, so knowing how they reflect the world is useful. What's interesting is that people's opinions are seemingly more consistent than the metrics. The correlation between ESPN's NBA Rank and SI's top 100 and SB Nation's top 100 is quite high. But I think the year to year correlation over the same ranking group is actually smaller than between groups in the same year, which implies a herd effect. Metrics shouldn't have that, so probably should be checked to see if it isn't a herd effect, but just capturing true performance changes.